Algorithm
BuildSimilarityKDTree:
Input: a point-set Pv
1. if Pv
contains only one point then
2. return
a leaf storing this point.
3. else:
4. Determine hyperplane orthogonal-axis SPv;
5. Split Pv into left/right subset Pl and Pr
with the
hyperplane through the mean-position of the
biggest
gap perpendicular to the orthogonal-axis;
6.
return:
(Vl; (SPv; jPlj); Vr),
where
Vl : = BuildSimilarityKDTree(Pl);
Vr: = BuildSimilarityKDTree(Pr);
|
Now an algorithm is very nice,
but let
try to understand what it really does:
First, we have a set of
points:
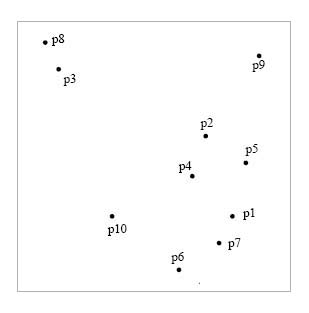
Since PV contains more than 1
point, we execute step 4.
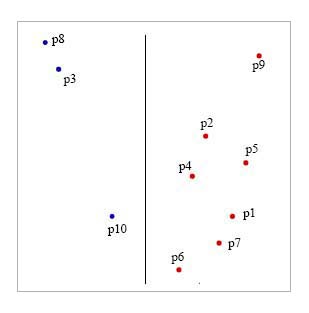
We must split Pv into left/right subset
Pl and Pr such that the hyperplane seperating these
sets is located in the mean-position of
the biggest gap perpendicular to some
orthogonal-axis.
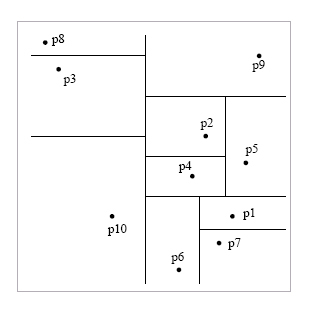
This largest gap between two points along the x-axis
or the y-axis occurs horizontally between points 10 and 6. Since we are
showing this in 2D, the hyperplane
is in fact a line. Therefore we draw a vertical
line halfway between these two points:
Now we recursively do the same
thing with the left points(blue)
until we've seperated every point.
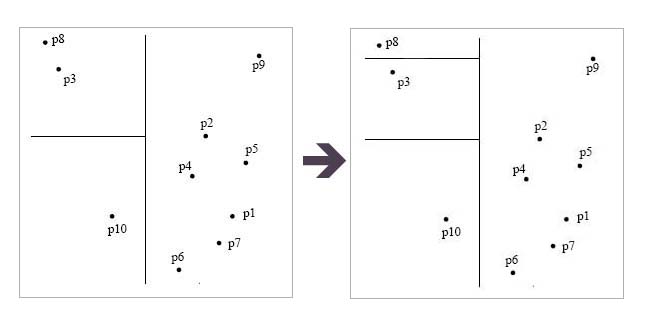
And again, recursively, we do
the same for the points on
the right.
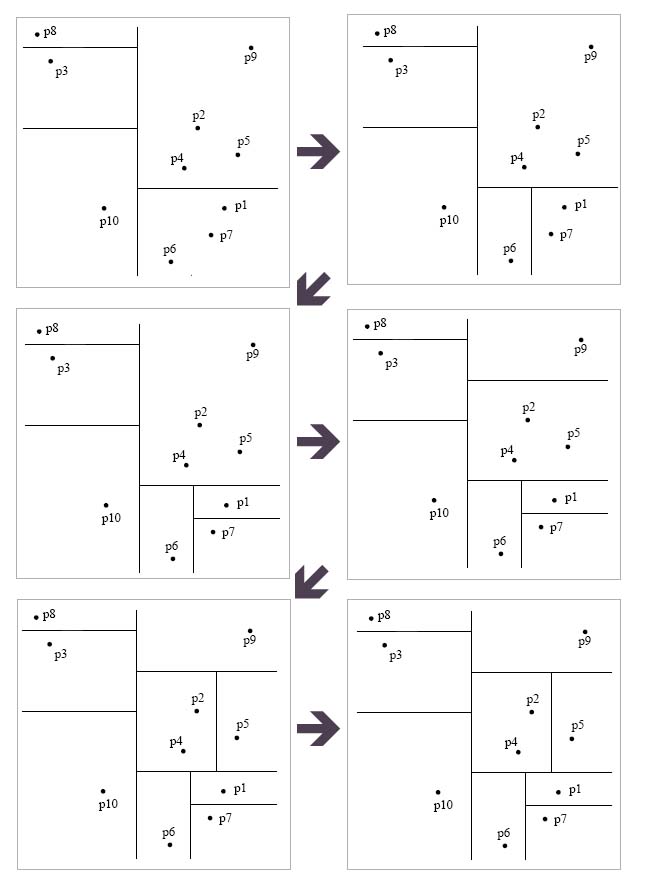
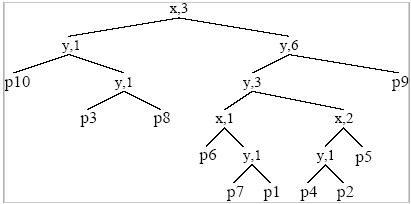
To finally get the following
space partition
and tree:
The main
work contributor to this algorithm is the sorting in each of the k
directions at each interior node. If we fix k, a balanced similarity
tree can be constructed in worst case O(M^2 * log M) where M is the
number of points in the input set.
On average, O(M * (log M)^2) can
be achieved.
We notice that for the similarity
k-d tree, data points are stored in leaves exclusively. Also at each
interior node of the tree, we record the axis of the chosen splitting
hyperplane, as well as the number of points contained in that node's
left subtree. The motivation for this becomes obvious in the next section.
|