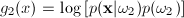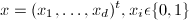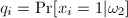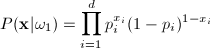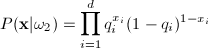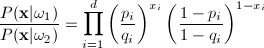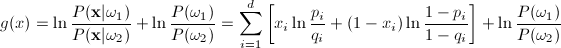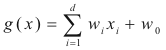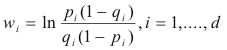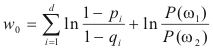As mentioned previously, in pattern recognition
many times a pattern recognition algorithm will output a feature vector
of the observed item. For instance, in the MIT reading machine for the
blind or even the cheque recognition procedure - a feature of d
dimension is output. If each feature in the vector is binary and
assumed (correctly or incorrectly) independent, a simplification of
Bayes Rule can employed:
The 2 Category Case
Here, we consider a 2-category problem in which
the components of the feature vector are binary-valued and conditionally
independent (which yields a simplified decision rule):
We also assign the following probabilities (p
and q) to each xi
in X:
If pi
> qi, we expect to xi
to be 1 more frequently when the state of nature is w1
than when it is w2.
If we assume conditional independence, we can write
P(X|wi)
as the product of probabilities for the components of X. The
class conditional probabilities are then:
Let’s explain the first equation. For
any xi, if it equals 1, then
the expression 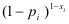 is 1. So only
is 1. So only 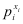 is considered; which makes
sense since pi is the
probability that x=1. If xi=0,
then only the second term is considered, and (1-pi)
is 1 - (probability that x=1)
which is the probability that x=0.
So, for every xi, the
appropriate probability is multiplied to obtain a final product.
is considered; which makes
sense since pi is the
probability that x=1. If xi=0,
then only the second term is considered, and (1-pi)
is 1 - (probability that x=1)
which is the probability that x=0.
So, for every xi, the
appropriate probability is multiplied to obtain a final product.
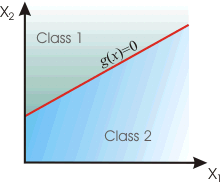
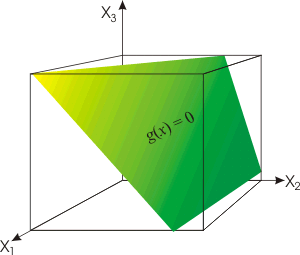
Since this is a two class problem the discriminant
function g(x) = g1(x)
- g2(x)
where:
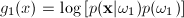 and
and