Classification Overview
Classification deals with associating a class label to a point, according
to the class to which the point is believed to belong. Classification is
typically based on a distance measure between the point under consideration
and other points belonging to known classes in point space. Figure 1 shows
and example of the classification task in two dimensional point space,
where the task is to label a point as belonging to either class A or class
B.

 Class A
Class A
 Class B
Class B
Figure 1 - Classification task
Linear Classification
Linear classification deals with classifying points according to their
position relative to a hyperplane in the point space. All points on a given
side of the hyperplane are considered as belonging to a class. Figure 2
shows an example of a linear classification in two dimensional point space,
where the hyperplane is a line. All points to the left of the hyperplane
belong to class A, and all points to the right belong to class B. Any new
point is assigned a class label according which side of the line it falls.
Linear classification is considered a simple and robust method of classification
in the absence of a known model for class data.
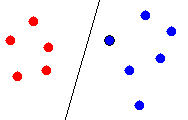
Class A
Class B
Figure 2 - Linear classification
Piecewise Linear Classification
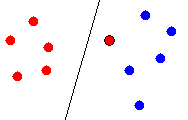
It is not hard to think of configurations of points for which simple linear
classification will perform poorly, however. There may exist no hyperplane
capable of uniquely separating point classes, because of geometrical reasons
or simply because there are more than 2 classes. Figure 3 shows an example
of this problem.
Class A
Class B
Figure 3 - Linear classification problem
Piecewise linear classification solves this problem by defining boundaries
between classes using several hyperplanes. Using multiple hyperplanes,
it is possible to define more than 2 regions in space, making it possible
to classify a set of points more precisely. Figure 4 shows how piecewise
linear classification works.
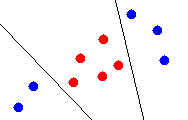
Class A
Class B
Figure 4 - Piecewise linear classification
Classification Error
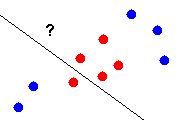
Classification is not perfect; points may be misclassified due to factors
such as data noise. Classification error can be determined by attempting
to classify a set of test points, and counting the number of misclassifications.
The classification error rate can be estimated by the number of misclassifications
divided by the total number of points in the test set. In Figure 5, a point
from class A is misclassified as belonging to class B. Since there are
11 points in the test set, and 1 has been misclassified, the classification
error rate is 1/11 = 0.09, or 9%.
Class A
Class B
Figure 5 - Classification error
Classification
Error vs. Generalizability
Although useful, piecewise linear classification must be used judiciously.
In the limit, enough hyperplanes can be defined to precisely classify each
point in the set of training data. But by the principle of Ocam's
Razor, an overly precise classification scheme tailored to a set of
training data tends to generalize poorly when it comes to classifying new
data. Thus, a compromise must be made between a classifier that accurately
describes its test data (i.e. using more hyperplanes) and a classifier
that will likely perform well on new data (i.e. using fewer hyperplanes).
This web page prepared by
Matt Toews (mtoews@cim.mcgill.ca)
as a term project for the course
Computer
Science 644 - Pattern Recognition
at the
McGill Center for
Intelligent Machines