The Original Algorithm
An early version of the algorithm proposed in
[2]
consisted in observing that an approximate occurrence of a pattern
must include pattern substrings that are a complete match(substrings
contain no errors) to some substrings of the pattern. This intuition leads
to the first lemma:
Lemma 1: If a pattern is partitioned into k + 1 pieces, then at least one of the pieces can be found with no errors in any approximate occurrence of the pattern.
Proof:
The algorithm originally proposed was an extension of the BM-Sunday algorithm (itself an extension of the Boyer-Moore Family search algorithm), which is already a simple, fast algorithm tailored for short patterns. The essence of the BM-Sunday algorithm lies in sliding a window over the text being searched and comparing the windowed text to the pattern. A table d computed for each character c is used to determine how much window displacement is allowed at the current position given the next character c, and the window is shifted accordingly. After all iterations are complete, the algorithm exits with the longest occurrence of an approximate match.
The adjustment to the BM-Sunday algorithm is made by splitting the pattern into pieces of size m/(k+1) and m/(k+1) and forming a tree with the pieces. A pessimistic table d is created (with longer pieces are left out), and contains the smallest shift allowed among all the pieces for each given character. The search is then performed from a text position by entering the table using the characters from that text position onwards, and a match is found only if a leaf node in the tree is reached. Once the search on a single text position is complete, the table d is consulted to determine the next window displacement(see Figure 0). Each piece found leads to a neighbourhood search for a complete match in the vicinity of the piece.
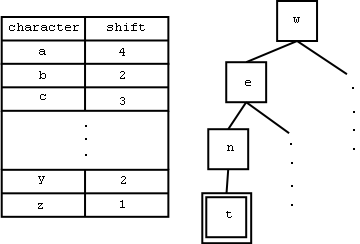
Figure 0. A sample table and tree that might be created using the original algorithm.
Using this procedure, if a text at position i in the text is found to be the end of a match to a subpattern ending at index j in the pattern,then the potential match must be searched in the text found between positions ( i - j +1 - k ) and ( i - j + m + k) of the text, which is ( m + 2k ) wide. As high error levels can occur in such searches, error-tolerant algorithms such as dynamic programming must be used.
This algorithm is fastest when the number of verifications is fairly low, in which case its running time is O( kn / m ) = O(an) . The search time when the number of verifications carried out does not dominate over the search time follows.
An exact pattern of length L occurs in random text with probability 1 / sL. In this case, we have L / s(m/k+1) ≈ 1 / s1/a , and since the cost of verifying a potential match using dynammic programming is O (m2), and there are k + 1 ≈ m a pieces to search, the total cost of verifications is m 3 a / s1/ a. In order for the total cost of the algorithm to not be affected by the cost of verifications, verifying potential matches must be O (a), which happens for a < 1/(3logsm). On English text, it was empirically estimated that the limit is a<1/5 for m ≤ 30.
Lemma 1: If a pattern is partitioned into k + 1 pieces, then at least one of the pieces can be found with no errors in any approximate occurrence of the pattern.
Proof:
Any partition that does not contain an error is a complete match, and thus we are guaranteed to have at least one partition that is a complete match to some substring of the pattern. This reduces the approximate string search to the problem of multipattern exact search (matching pattern substrings to partitions) plus verification of potential matches(using the exact search results).By the Pidgeonhole Principle, if we have a pattern partitioned into k +1 "slots" and k errors to distribute among the partitions, then we have at least 1 partition that will not be distributed an error.
The algorithm originally proposed was an extension of the BM-Sunday algorithm (itself an extension of the Boyer-Moore Family search algorithm), which is already a simple, fast algorithm tailored for short patterns. The essence of the BM-Sunday algorithm lies in sliding a window over the text being searched and comparing the windowed text to the pattern. A table d computed for each character c is used to determine how much window displacement is allowed at the current position given the next character c, and the window is shifted accordingly. After all iterations are complete, the algorithm exits with the longest occurrence of an approximate match.
The adjustment to the BM-Sunday algorithm is made by splitting the pattern into pieces of size m/(k+1) and m/(k+1) and forming a tree with the pieces. A pessimistic table d is created (with longer pieces are left out), and contains the smallest shift allowed among all the pieces for each given character. The search is then performed from a text position by entering the table using the characters from that text position onwards, and a match is found only if a leaf node in the tree is reached. Once the search on a single text position is complete, the table d is consulted to determine the next window displacement(see Figure 0). Each piece found leads to a neighbourhood search for a complete match in the vicinity of the piece.
Figure 0. A sample table and tree that might be created using the original algorithm.
Using this procedure, if a text at position i in the text is found to be the end of a match to a subpattern ending at index j in the pattern,then the potential match must be searched in the text found between positions ( i - j +1 - k ) and ( i - j + m + k) of the text, which is ( m + 2k ) wide. As high error levels can occur in such searches, error-tolerant algorithms such as dynamic programming must be used.
This algorithm is fastest when the number of verifications is fairly low, in which case its running time is O( kn / m ) = O(an) . The search time when the number of verifications carried out does not dominate over the search time follows.
An exact pattern of length L occurs in random text with probability 1 / sL. In this case, we have L / s(m/k+1) ≈ 1 / s1/a , and since the cost of verifying a potential match using dynammic programming is O (m2), and there are k + 1 ≈ m a pieces to search, the total cost of verifications is m 3 a / s1/ a. In order for the total cost of the algorithm to not be affected by the cost of verifications, verifying potential matches must be O (a), which happens for a < 1/(3logsm). On English text, it was empirically estimated that the limit is a<1/5 for m ≤ 30.