In the original algorithm the whole
pattern is checked for a match each time a match is found, which can be
improved upon by instead trying to eliminate a potential match from
candidacy by quickly determining that the match of a small piece is
not in fact part of a complete match. In order for this improvement
to be achieved, a stronger lemma must be used:
Stronger Lemma:
If segm
= Text[a...b] matches pat with k errors, and pat = p1...p
j ( a concatenation of subpatterns), then segm includes a
substring that matches at least one of the pi's, with floor(ai
k/A) errors, where the ai ≥ 0 are arbitrary and A = Σj
i=1 a i .
Proof:
The proof proceeds by construction. The first
case is where k + 1 is a power of 2, where the lemma is used
with A = 2, j = 2, a1 = a2 = 1. So the pattern is
split in two (along with the number of errors), and the stronger lemma
states that at least one half must match with floor(k/2) errors.
The splitting is recursively continued until the resulting pieces are
to be directly searched with no errors. This defines a tree, where the
leaves represent the pattern pieces that are to be directly searched, ,
the internal nodes are larger subpatterns used for intermediate verification,
and the root corresponds to the complete pattern. The search remains the
same in this case, but the verification is more complex, with the (tree)parents
of complete matches being checked rather than the root of the tree. After
a complete match (0 errors) is found at a leaf node, the search is continued
at the leaf's parents k = 1 , then doubles every time an approximate
substring match is found within the allowed error interval, as the parent
of a given node is approximately twice the size of the child that reported
to the parent. This continues upwards through the tree until either the
root is reached or the pattern is found to contain more than the allowed
number of errors at a given level of the tree, and the solutions output
by the algorithm are all searches that reach the root node of the tree and
do not have more than the allowed number of errors at that level.
The above construction is valid because the lemma holds
at every level of the tree, and so any approximate match reported by
the root must include an approximate substring match reported by one
of its two children, and so each child is searched, This applies recursively
to each of the subtrees rooted at the root's child nodes, and all of the
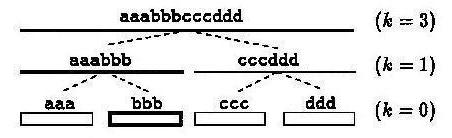
subtrees below them. Figure 1 above shows an example of the formation
of the tree using this algorithm and the pattern "aaabbbcccddd". If a
text being searched is "xxxbbbxxxxxx", and this pattern is presented with
the tree above, the leaf with labe "bbb" will be found as a complete match,
and the search can continue on to its parent ("aaabbb") to determine whether
an approximate substring match to the subpattern represented by that node
is not found. This is in contrast to the original algorithm, which would
find the leaf node "bbb" and attempt to prove a complete match (rather
than disproving one at the soonest possible instant).
In the case where k + 1 is not a power of two, the tree
is constructed as balanced as possible to avoid the long linear searches
inherent with large leaf nodes (created by the presence of small ones).
If the pattern is broken up into a left child with i pieces and
a right child with j pieces, where i + j =
k, the left subtree is searched with floor( ik /(k+1))
errors, and the right subtree is searched with floor( jk / (k
+1) ) errors, yielding an error tolerance of 0 when the leaf nodes are
reached. The lemma again applies to each level of the node, and a search
can only have continued to a node if a child of that node contained less
than the maximum number of allowed errors for its level.
This new technique of verification yields a faster performance
for the algorithm on medium error levels with its elimination of candidates,
and remains as fast as the original on low error levels. Using this hierarchichal
verification algorithm, the verification cost per piece is
L
2 /
sfloor(m
/( k+1) ) . Since
L =
m / (
k + 1) ≈ 1 /
a , and since
there are
k + 1 ≈
ma pieces to
search, the total verification cost is m / (
a
s1 /s). In order
to leave the total cost of the algorithm unaffected by the new verification
method, we must have a verification cost of
O(
a ), which occurs for
a<1/log
sm.
The improvement thus obtained can be seen in Figure 2
below, where on random text(left), the algorithm works well up to
a < 1/2, whereas the previous method only works well up to
a < 1/3. The hierarchical qualities
of the new method carries with it an increased number of calculations when
the error level is high, however, and its performance is much poorer at high
error levels than the old algorithm. This is ecpected, however, since
this verification method relies on some of the characters being found in
the text(of which there is a high probability), and then verifying that these
characters are not part of a match.
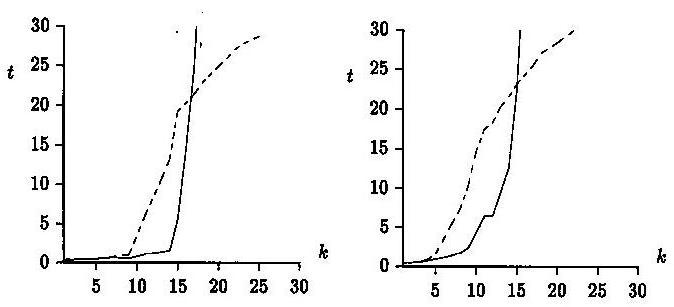 Figure 2.
Figure 2. The old (dashed line) versus the new (solid line) verification techniques. We use
m = 30 and show random (left) and English text (right).