Experimental Comparison
Here we take a look at the experimental results from
the old algorithm and new algorithms in comparison to the fastest
known algorithms in the field. The algorithms presented below are
as follows:
- BYP, the original version of this algorithm;
- BYN and Myers, the two other fastest algorithms based on bit parallelism;
and
- Ours, the improved version of BYP with hierarchical classification;
- Agrep, the fastest know search software(tested on English text only
here);
- Ours/NO, the version of Ours that does not use hierarchical verification
or splitting optimization(tested on English text only here).
Below we have the results for testing on random text with
m=10, m=20 and m=30, respectively:

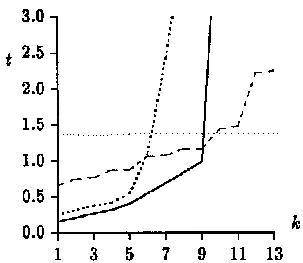
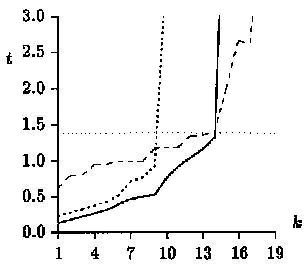
The above results show that for
s = 32 the new algorithm (Ours) is more efficient than any other for
a < 1/2, after which point the Myers and BYN
algorithms outperform it. Results for experiments on English text follow,
again for m = 10, m = 20, and m = 30, respectively:
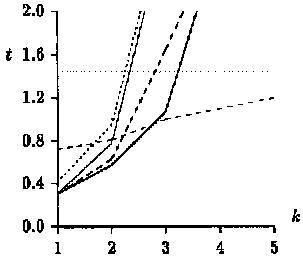
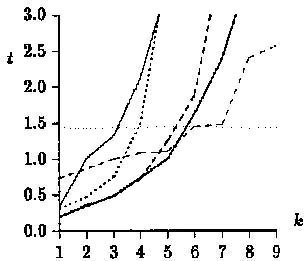
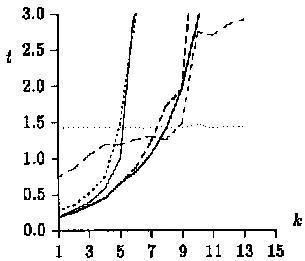
The test runs on English text yield
slightly different results, with the new algorithm being fastest for
a < 1/3, and the Agrep algorithm outperforming the original algorithm(BYP).
We can thus observe that the hierarchical verification and splitting optimization
introduced in this new string searching algorithm have brought with them
an improvement over the previous fastest algorithms in the field, and have
a higher tolerance for error than the aforementioned.